Empowering Your Proteomics Data Analysis
We are thrilled to share the latest advancements in PanHunter®, our versatile multi-omics platform. Understanding the complexities of proteomics data is crucial for gaining deeper insights into biological processes. Our newly developed features are tailored to streamline and enhance your data analysis workflow, making it more efficient and user-friendly. By improving the pre-processing and integration of proteomics data, we aim to save you valuable time and effort, allowing you to focus on what truly matters—your research.
Our team has worked diligently to enhance PanHunter's support for proteomics data. Here’s how we’ve done it:
- Seamless Integration with DiaNN Outputs: Users can now effortlessly start the pre-processing pipeline with DiaNN outputs. This pipeline performs essential tasks such as imputation, batch correction, sparsing, and scaling.
- Efficient Re-runs with Snakemake: By utilizing Snakemake, our pipelines allow for fast re-runs with altered parameters, leveraging intermediate results to avoid recomputing all steps. This significantly speeds up the determination of the best pre-processing parameters.
- User-Friendly Interface: The pre-processing pipeline can be triggered from both RStudio and our user interface (UI), known as the Admin App. This integration enhances the user experience and streamlines the process.
Here are the specific advancements we’ve made:
- Enhanced Pre-processing Pipeline: After running the pre-processing pipeline, data is immediately available in the Proteomics QC App via the UI. For RStudio users, convenient functions are available to upload data to the Proteomics QC App.
- Parameter Optimization: Users can analyze data and adjust parameters as needed. Changes can be made in the UI or from RStudio in a .yaml file. Different runs can be selected and compared in the Proteomics QC App until the best parameters are found.
- Easy Integration: Once optimal parameters are determined, integrating the data into the remaining apps of PanHunter requires only two clicks. Users can then proceed with differential analysis and further data exploration. Our team is continuously working on adding more pre-processing workflows to PanHunter.
Upcoming features include:
- Pipelines for PTM Data: Expanding our pre-processing capabilities to include post-translational modifications.
- Support for Additional Software: Integration with MaxQuant and Spectronaut.
- Enhanced Data Visualization: More refined and additional plots in the Proteomics QC App to aid data analysis.
Stay tuned for more updates as we continue to enhance PanHunter's capabilities and drive innovation in the field of multiomics.
Release Notes
Download of Public Data From GEO
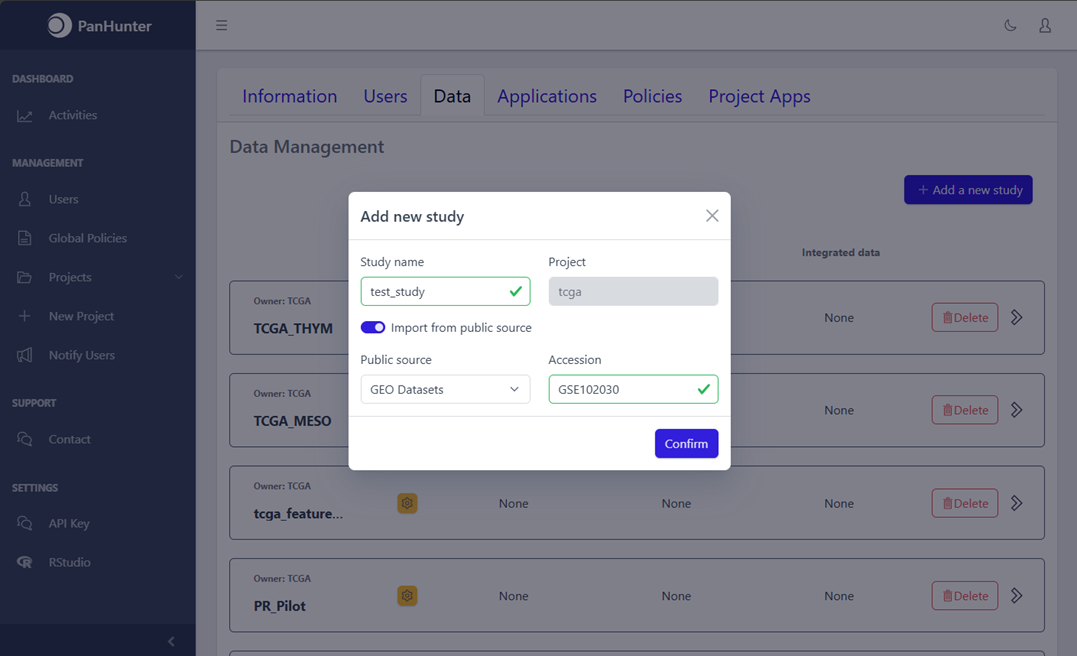
It is now possible to directly download public data from the NCBI GEO via the graphical user interface of the Admin App in PanHunter. All you need to do is specify the GSE Accession number of the study you are interested in, PanHunter will do the rest and assist you along the way to fully process raw data and integrate the study into your project.
Perform Proteomics Data Quality Control Before Fully Integrating
You can upload proteomics data and sample meta-information, perform data processing and trigger data integration directly from the user interface. This is an important step towards full user autonomy.
This recent addition, now allows you to evaluate the quality of proteomics data before fully integrating the data into PanHunter. This allows data managers and computational biologists to check the data before making it available to other project members, making the release of new datasets more convenient.
General News & Updates
Our participation at annual gathering of DGMS in Göttingen was a resounding success. We took the opportunity to exchange and network with solution providers and users at Germany’s biggest mass spectrometry gathering. This academic event delivered great insights into the current hot topics in the mass spectrometry society. Looking forward to meet you there next year
Meet Bernhard: Driving Innovation in Software Engineering at Evotec!
We’re thrilled to continue our Employee Stories Series with Bernard, a talented software engineer at Evotec who is playing a crucial role in shaping the future of healthcare through technology.
Bernhard’s story highlights:
- How his software engineering expertise fuels innovation at Evotec
- The impact of staying curious and constantly learning in tech
- The role of software in advancing healthcare breakthroughs and improving patient outcomes
Evotec PanOmics: Meet Hannah Elisa Krawczyk
We are proudly presenting a new video series, ‘Meet Our Computational Biology Experts’! Join us on our journey to meet the talented team and learn more about PanOmics, Evotec’s multi-omics supported drug discovery!
Hannah Elisa is a research scientist at computational biology department at Evotec, responsible for analysis and interpretation of genetic and genomics data.
Watch this introduction from Hannah Elisa to learn:
- Why genetic and genomics data are important in drug discovery
- How Evotec assesses genetic evidence to predict the efficacy and safety of drug targets
- What can you do to raise probability of success

